
中国 Linux 内核开发者大会,作为中国 Linux 内核领域最具影响力的峰会之一,一直以来都备受瞩目。
10 月 26 日,第 19 届中国 Linux 内核开发者大会(简称 CLK 2024) 在武汉成功举办,吸引了众多内核开发者和技术爱好者参与。
在本次大会调度与锁分论坛中,deepin(深度)社区高级内核研发工程师聂诚和余昇锦带来了《NUMA 场景下 osq 锁的性能优化》技术分享。
首先,他们深入探讨了在 NUMA(非均匀内存访问)架构下,多进程访问同一文件时存在的性能差异问题。通过对比 12 个进程在单个 Node 和跨 Node 访问文件的性能数据,他们发现跨 Node 访问时,LLc(最后一级缓存)未命中率显著升高,其中 osq_lock(乐观自旋队列锁)占比较高。
随后,聂诚和余昇锦详细介绍了 NUMA 架构的特点,强调了在 NUMA 系统中,CPU 访问不同节点内存的速度差异,以及这种差异对系统性能的影响。他们解释了睡眠锁 osq 机制的工作原理,即在持有锁的进程没有睡眠时,通过自旋等待而不是睡眠来优化性能。然而,在 NUMA 环境中,osq 锁传递会引发跨 NUMA 节点的访问,导致性能下降。
为了解决这一问题,他们提出了一种基于 NUMA 的 osq 优化方案。该方案将 osq_lock 的链表按照 NUMA 节点划分,每个 NUMA 节点对应一个 osq 链表,每个 CPU 加入到各自所属的 NUMA 节点对应的链表中。这样,当 NUMA 节点的最后一个 CPU 释放 osq_lock 时,可以将锁传递到下一个 NUMA 节点,从而减少跨 NUMA 节点的访问次数。
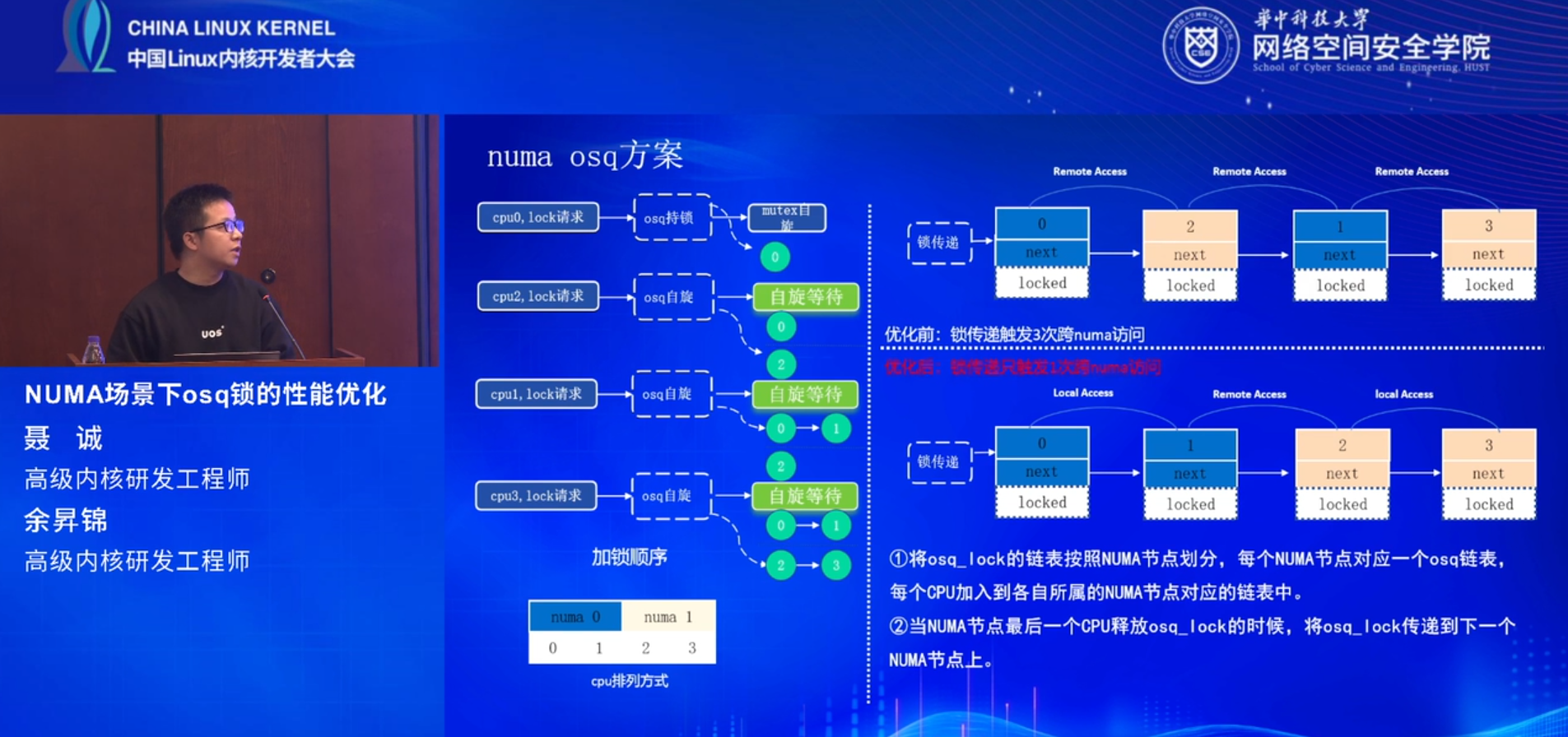
此外,他们还讨论了锁传递问题和内存问题,并提出了相应的优化措施。例如,通过新增一个标志位 tail_locked 来解决判断所有队列是否为空的原子性问题,以及通过 hash 技术来优化内存使用,减少互斥锁 和 读写锁结构的大小。
在解决饿死问题方面,他们引入了伪随机机制,以确保锁在 NUMA 节点间的公平传递,并通过 INTRA_NODE_HANDOFF_PROB_ARG 参数调整公平性和性能之间的平衡。
最后,聂诚和余昇锦通过实验验证了优化方案的有效性。在 arm64 和 arm96 两种架构下,优化后的 Numa osq 方案在不同文件复制场景下均取得了显著的性能提升,优化百分比在 80% 到 118% 之间。
deepin 社区的内核研发工程师们专注于解决 NUMA 场景下的锁性能问题。NUMA(Non-Uniform Memory Access,非均匀内存访问)架构在现代服务器中非常常见,在这种架构下,osq锁(Optimistic Spinlock,乐观自旋锁)的性能优化对于提升系统性能至关重要。聂诚和余昇锦在这一领域的研究成果和实践经验,这对于推动 Linux 内核技术的发展具有重要意义。
未来,deepin 将持续提升内核兼容性和稳定性、完成技术更新换代、支持多架构发展、优化 Wayland 支持、扩大内核开发的深度和广度、推进国际化进程,提升用户体验,为开源桌面操作系统发展持续注入能量。
相关阅读:
内容来源:deepin(深度)社区
转载请注明出处